Research Projects of lode hoste
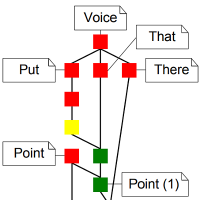
Mudra is a unified multimodal interaction framework supporting the integrated processing of low-level data streams as well as high-level semantic inferences. Our solution is based on a central fact base in combination with a declarative rule-based language to derive new facts at different abstraction levels. The architecture of the Mudra framework consists of three layers: At the infrastructure level, we support the incorporation of any arbitrary input modalities, including skeleton tracking via Microsoft’s Xbox Kinect, multi-touch via TUIO and Midas, voice recognition via CMU Sphinx and accelerometer data via SunSPOTs. In the core layer a very efficient inference engine (CLIPS) was substantially extended for the continuous processing of events. The application layer provides flexible handlers for end-user applications or fission frameworks, with the possibility to feed application-level entities back to the core layer.

The main goal of the Midas framework is to provide developers adequate software engineering abstractions to close the gap between the evolution in the multi-touch technology and software detection mechanisms. We advocate the use of a rule language which allows programmers to express gestures in a declarative way. Complex gestures which are extremely hard to be implemented in traditional approaches can be expressed in one or multiple rules which are easy to understand.

We present a solution that uses explicit gestures and implicit dance moves to control the visual augmentation of a live music performance. We further illustrate how our framework overcomes limitations of existing gesture classification systems by providing a precise recognition solution based on a single gesture sample in combination with expert knowledge. The presented approach enables more dynamic and spontaneous performances and|in combination with indirect augmented reality leads to a more intense interaction between artist and audience.