Research Projects of beat signer

With the ever-growing amount of data produced by humans as well as IoT devices and smart environments, there is a strong need for tools and natural user interfaces to explore and analyse these large datasets forming part of the Big Data era. There has been a lot of research on how to efficiently batch process large datasets and create some static reports for the analysis of the underlying dataset, but recently there is an increasing interest in real-time processing and query adaptation in Big Data environments, enabling so-called human-in-the-loop data exploration.
OpenHPS is an open source hybrid positioning system. The framework allows developers to create a process network with graph topology for computing the position of a person or asset. We provide modules that provide positioning methods (e.g. Wi-Fi, Bluetooth or visual positioning) or algorithms. These methods and algorithms are represented as nodes in the processing network.

Nowadays, scholars use various ICT tools as part of their scholarly workflows. Individual scholarly activities that might be supported by these ICT tools include the finding, storing and analysing of information as well as the writing sharing and publishing of research results. However, despite the widespread use of ICT tools in the research process (more than 600 ICT tools have been identified), a scholar’s information frequently gets fragmented across these different tools.
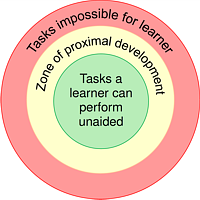
A major aim of our research is to make programming education accessible to everyone, especially people from underrepresented or underprivileged groups. That means thinking about ways we teach CS, thinking about how students experience CS, intrinsic or external motivations students may have for learning about computing, but also tools to help both educators and learners. Very important to note is that I aim to make sure that the tools are accessible to a wide audience and do not require complex LMS setups that might not be useable by small-scale organisations.

This research project aims to explore the integration of physical and digital information to enhance human-information interaction through next generation user interfaces. Realising physical carriers’ irreplaceable qualities and digital resources’ versatile abilities, we seek to bridge the gap between these two realms. We believe that instead of striving for the complete replacement of physical information carriers, a hybrid approach that combines digital and physical documents offers a more meaningful solution.

iPaper is a platform for interactive paper applications that has been realised as an extension of the iServer cross-media link server. The iPaper framework supports the rapid prototyping, development and deployment of interactive paper applications.

Existing presentation tools such as Microsoft's PowerPoint, Apple's Keynote or OpenOffice Impress represent a de facto standard for giving presentations. We question these existing slide-based presentation solutions due to some of their inherent limitations. Our new MindXpres presentation tool addresses these problems by introducing a radically new presentation format. In addition to a clear separation of content and visualisation, our HTML5 and JavaScript-based presentation solution offers advanced features such as the non-linear traversal of the presentation, hyperlinks, transclusion, semantic linking and navigation of information, multimodal input, dynamic interaction with the content, the import of external presentations and more.
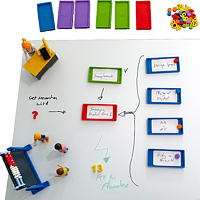
The overall goal of this project is to develop a design toolkit for knowledge physicalisation and augmentation that will enable the design of solutions that work in synergy with a user’s knowledge processes and support them during knowledge tasks in educational as well as workplace settings. While there is a significant body of work in the fields of tangible user interfaces or data physicalisation, there is a gap in understanding the design space for solutions that support scribbling behaviour during daily activities in education and workplaces across the reality-virtuality continuum.
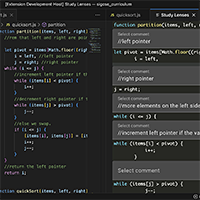
Explorotron is a Visual Studio Code (VS Code) extension that is designed to help students learn from arbitrary JavaScript code examples by providing different interactive views or so-called study lenses each focusing on different aspects of the code. The individual study lenses are based on computing education research and follow best practices such as the PRIMM methodology, a peel-away design or an environment closely resembling a professional programming environment to support skill transfer.
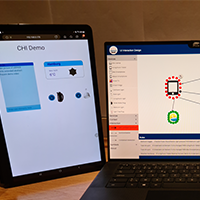
eSPACE is an innovative end-user authoring tool that enables individuals without programming knowledge to create their own smart applications through a user-friendly web interface. The tool offers a range of views to support the creation process, including the interaction view that utilises a visual pipeline metaphor to define interaction rules, and the rules view that serves as a more textual counterpart for defining rules using if-then statements.
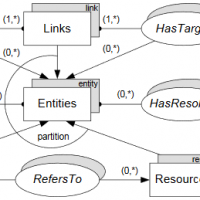
The iServer platform supports the integration of cross-media resources based on the resource-selector-link (RSL) model. iServer not only enables the definition of links between different types of digital media, but can also be used for integrating physical and digital resources.
Discovering smart devices in the physical world often requires indoor positioning systems. Bluetooth Low Energy (BLE) beacons are widely used for creating scalable, cost-effective positioning systems for indoor navigation, tracking, and location awareness. However, existing BLE specifications either lack sufficient information or rely on proprietary databases for beacon location. In response, we introduce SemBeacon—a novel BLE advertising solution and semantic ontology extension. SemBeacon is backward compatible with iBeacon, Eddystone, and AltBeacon. Through a prototype application, we demonstrate how SemBeacon enables real-time positioning systems that describe both location and environmental context. Unlike Eddystone-URL beacons, which broadcast web pages, SemBeacon focuses on broadcasting semantic data about the environment and available positioning systems using linked data.
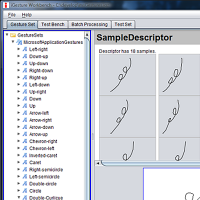
iGesture is an open source gesture recognition framework supporting application developers who would like to add new gesture recognition functionality to their application as well as designers of new gesture recognition algorithms.

The PaperPoint application is a simple but very effective tool for giving PowerPoint presentations. The slide handouts are printed on Anoto paper together with some additional paper buttons for controlling the PowerPoint presentation. A digital pen is used to remotely control the PowerPoint presentation over wireless Bluetooth technology.

Initiative to improve teaching aids (e.g. interactive paper) for rural areas of India in collaboration with the bj institute.
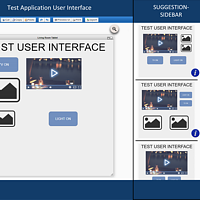
With the rise of different electronic devices such as smartphones, tablets and smartwatches, and the emergence of "smart things" forming part of the Internet of Things (IoT), user interfaces (UIs) have to be adapted in order to cope with the different input and output methods as well as device characteristics. In addition to the challenges dealing with these rapidly changing technologies, user interface designers struggle to adapt their UIs to evolving user needs and preferences, resulting in bad user experience.

The ArtVis project investigates advanced visualisation techniques in combination with a tangible user interface to explore a large source of information (Web Gallery of Art) about European painters and sculptors from the 11th to the mid-19th century. Specific graphical and tangible controls allow the user to explore the vast amount of artworks based on different dimensions (faceted browsing) such as the name of the painter, the museum where an artwork is located, the type of art or a specific period of time.The name ArtVis reflects the fact that we bring together artworks and the field of Information Visualisation (InfoVis) in order to achieve a playful and highly explorative user experience in order to get a broader understanding of the collection of artworks.
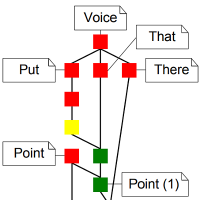
Mudra is a unified multimodal interaction framework supporting the integrated processing of low-level data streams as well as high-level semantic inferences. Our solution is based on a central fact base in combination with a declarative rule-based language to derive new facts at different abstraction levels. The architecture of the Mudra framework consists of three layers: At the infrastructure level, we support the incorporation of any arbitrary input modalities, including skeleton tracking via Microsoft’s Xbox Kinect, multi-touch via TUIO and Midas, voice recognition via CMU Sphinx and accelerometer data via SunSPOTs. In the core layer a very efficient inference engine (CLIPS) was substantially extended for the continuous processing of events. The application layer provides flexible handlers for end-user applications or fission frameworks, with the possibility to feed application-level entities back to the core layer.

The main goal of the Midas framework is to provide developers adequate software engineering abstractions to close the gap between the evolution in the multi-touch technology and software detection mechanisms. We advocate the use of a rule language which allows programmers to express gestures in a declarative way. Complex gestures which are extremely hard to be implemented in traditional approaches can be expressed in one or multiple rules which are easy to understand.

The number of youngsters (from 18 to 24 years old) who leave school without having obtained an upper-secondary education degree and who do not follow any type of education is much higher within the Brussels Capital Region than the Belgian average. Furthermore, in comparison to the Flemish and Walloon Regions the numbers for Brussels also prove comparatively elevated. In 2014, the school dropout rate for the Brussels Capital Region was 14,4%, while 7% for Flanders and 12,9% for Wallonia.

We present a solution that uses explicit gestures and implicit dance moves to control the visual augmentation of a live music performance. We further illustrate how our framework overcomes limitations of existing gesture classification systems by providing a precise recognition solution based on a single gesture sample in combination with expert knowledge. The presented approach enables more dynamic and spontaneous performances and|in combination with indirect augmented reality leads to a more intense interaction between artist and audience.

The MobiCraNT project aims at the development of software engineering principles and patterns for the development of mobile cross-media applications that operate in a heterogenous distributed setting and interact using cross-media technology.
A first purpose of this project is to investigate the cognitive processing involved in educational games and its impact on learning. The second purpose is to investigate how we can influence these cognitive processes by using adaptive techniques. Among others, we investigate the impact of the personality, the learning style, as well as the motivational aspects of learning by manipulating different aspects of the educational game.